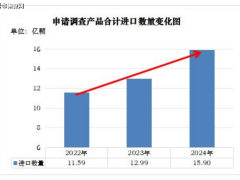
中國人工智能領(lǐng)域的明星企業(yè)DeepSeek近期宣布了其旗艦大語言模型的重大更新,新版本針對即將面世的新一代國產(chǎn)芯片進行了專門優(yōu)化。
據(jù)DeepSeek介紹,此次升級采用了名為UE8M0的新型數(shù)據(jù)類型來訓(xùn)練V3.1模型,這是對現(xiàn)有FP8格式的一種擴展,已被英偉達等業(yè)界巨頭所支持。DeepSeek在微信平臺上澄清,這一變化是為了更好地適配即將推出的國產(chǎn)芯片,指出“UE8M0 FP8專為新一代國產(chǎn)芯片設(shè)計”。
使用較低精度的數(shù)據(jù)類型帶來了諸多優(yōu)勢,包括減少內(nèi)存占用和提升推理及訓(xùn)練速度。值得注意的是,DeepSeek之前已經(jīng)在使用FP8格式中的E4M3類型。因此,轉(zhuǎn)向UE8M0更多是為了確保與新一代芯片的兼容性,而非單純追求效率提升。
雖然DeepSeek未透露新模型所適配芯片的具體制造商,但有報道稱這家AI初創(chuàng)公司與華為有著緊密合作,利用華為的昇騰系列神經(jīng)處理單元(NPU)進行模型訓(xùn)練和推理。華為的昇騰910C為其CloudMatrix機架系統(tǒng)提供動力,但目前不支持FP8格式,這或許意味著華為正在研發(fā)性能更強大的加速器。
有消息指出,DeepSeek曾嘗試在華為昇騰加速器上訓(xùn)練其下一代R2模型,但因遇到困難而改用英偉達的H20加速器。不過,DeepSeek目前仍在評估華為加速器的推理性能。
關(guān)于R2模型,目前尚不清楚它是否就是此次發(fā)布的V3.1版本,或是另一個即將推出的模型。
值得注意的是,DeepSeek V3.1并非從零開始的全新模型,而是基于早期V3版本的檢查點進一步訓(xùn)練而成。盡管如此,這一新版本在功能上有顯著改進。V3.1版本不再區(qū)分“思考型”和“非思考型”模型,而是將兩種范式整合到單一模型中,并通過聊天模板實現(xiàn)模式切換。因此,DeepSeek的聊天機器人界面也不再提及R1版本。
統(tǒng)一模型以支持推理和非推理輸出的概念并非DeepSeek首創(chuàng)。阿里巴巴今年早些時候也曾嘗試過類似做法,但因發(fā)現(xiàn)該功能降低了模型質(zhì)量而放棄。然而,在基準(zhǔn)測試中,DeepSeek的V3.1版本似乎成功避免了這一問題。與V3版本相比,V3.1的非思考模式在各項指標(biāo)上都有顯著提升。
在啟用思考功能后,V3.1版本的性能提升雖然相對溫和,但DeepSeek指出,該模型現(xiàn)在需要更少的思考Token就能給出答案,這將有助于降低模型服務(wù)的成本。
在上下文處理能力方面,DeepSeek將V3.1版本的上下文窗口(即短期記憶)從65,536個Token擴展到131,072個,盡管這一數(shù)字仍然落后于阿里巴巴的Qwen3等其他中國模型,后者能處理高達百萬級的Token上下文。
DeepSeek還聲稱在工具和函數(shù)調(diào)用能力方面取得了重大進展,這對于需要實時檢索外部數(shù)據(jù)和調(diào)用工具的AI工作負(fù)載至關(guān)重要。例如,在針對自主瀏覽器使用任務(wù)的Browsecomp基準(zhǔn)測試中,DeepSeek V3.1版本獲得了30分的高分,而R1版本的5月版本僅得8.9分。
除了通過聊天機器人服務(wù)和API端點提供服務(wù)外,DeepSeek還在Hugging Face和ModeScope平臺上提供了基礎(chǔ)模型和指令調(diào)優(yōu)模型的權(quán)重下載,方便開發(fā)者進一步定制和優(yōu)化。
關(guān)于DeepSeek V3.1版本的更多信息,以下是幾個常見問題及解答:
Q:DeepSeek V3.1有哪些新特點?
A:V3.1版本最大的特點是使用UE8M0數(shù)據(jù)類型進行優(yōu)化,專為即將發(fā)布的國產(chǎn)芯片設(shè)計。同時,它整合了“思考型”和“非思考型”模型功能,在單一模型中通過聊天模板實現(xiàn)模式切換,并將上下文窗口的Token數(shù)量大幅提升。
Q:為什么DeepSeek要切換到UE8M0數(shù)據(jù)類型?
A:DeepSeek切換到UE8M0主要是為了與即將推出的新一代國產(chǎn)芯片保持兼容。盡管公司之前已在使用FP8的E4M3類型,但UE8M0是專為新一代國產(chǎn)芯片設(shè)計的,預(yù)示著可能有更強大的國產(chǎn)加速器即將面世。
Q:DeepSeek V3.1版本的性能如何?
A:在基準(zhǔn)測試中,V3.1版本的非思考模式相比V3版本在各項指標(biāo)上都有顯著提升。在工具調(diào)用方面,V3.1版本在Browsecomp瀏覽器任務(wù)測試中得分高達30分,遠(yuǎn)超R1版本的8.9分。同時,該模型現(xiàn)在需要更少的思考Token就能給出答案,有助于降低服務(wù)成本。