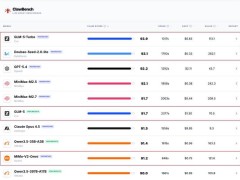
近日,國際權(quán)威評測機構(gòu)ClawBench公布了最新一期大型語言模型綜合排行榜,中國科技企業(yè)表現(xiàn)亮眼。北京智譜科技研發(fā)的GLM-5-Turbo以93.9分的絕對優(yōu)勢登頂全球榜首,字節(jié)跳動旗下豆包模型Doubao-Seed-2.0-lite緊隨其后位居次席,小米公司更憑借MiMo-V2系列兩款模型實現(xiàn)雙榜突破,展現(xiàn)出中國AI研發(fā)團隊的強勁實力。
本次評測中,字節(jié)跳動的豆包模型不僅在性能指標上斬獲全球第二,更以顯著優(yōu)勢成為全榜單中運行成本最低的模型。小米公司則實現(xiàn)多點開花,其MiMo-V2-Omni模型在運行效率專項測試中表現(xiàn)突出,位列全球第九;更值得關(guān)注的是,該系列高端版本MiMo-V2-Pro在復(fù)雜邏輯推理、長指令執(zhí)行穩(wěn)定性等核心指標上達到國際領(lǐng)先水平,在Model Rank專業(yè)評測中躋身全球前五。
在反映企業(yè)綜合研發(fā)能力的LabRank實驗室評測體系中,小米公司持續(xù)保持強勁勢頭。其Text Arena(ArenaExpert)文本生成能力評測位列全球第四,代碼生成專項Code Arena評測位居全球第五,整體技術(shù)實力已形成對Anthropic、OpenAI、谷歌等國際頂尖機構(gòu)的追趕態(tài)勢。據(jù)評測機構(gòu)介紹,Text Arena榜單采用全球首創(chuàng)的雙盲測試機制,通過隱藏模型身份信息、由真實用戶直接投票的方式,有效規(guī)避了傳統(tǒng)評測中常見的"數(shù)據(jù)集優(yōu)化"問題,確保評測結(jié)果真實反映模型的實際應(yīng)用表現(xiàn)。
行業(yè)觀察人士指出,本次評測結(jié)果標志著中國AI企業(yè)在基礎(chǔ)模型研發(fā)領(lǐng)域已實現(xiàn)從跟跑到并跑的跨越。特別是小米等硬件廠商的入局,正在推動大模型技術(shù)從實驗室走向真實應(yīng)用場景,這種"軟硬協(xié)同"的發(fā)展模式或?qū)⒅厮苋駻I產(chǎn)業(yè)競爭格局。隨著ClawBench等第三方評測體系的不斷完善,技術(shù)實力的客觀比較將成為推動行業(yè)健康發(fā)展的重要力量。